
大视频模型是世界模型?DeepMind/UC伯克利华人一作:预测下一帧就能改变世界
声明:本文来自于微信公众号 新智元(ID:AI_era),作者:新智元,授权站长之家转载发布。
【新智元导读】谷歌DeepMind、UC伯克利和MIT的研究人员认为,如果用大语言模型的思路来做大视频模型,能解决很多语言模型不擅长的问题,可能能更进一步接近世界模型。
没人怀疑,OpenAI开年推出的史诗巨作Sora,将改变视频相关领域的内容生态。
但Google DeepMind、UC伯克利和MIT的研究人员更进一步,在他们眼里,「大视频模型」也许能够像世界模型一样,真正的做到理解我们身处的这个世界。

论文地址:https://arxiv.org/abs/2402.17139
在作者看来,视频生成将彻底改变物理世界的决策,就像语言模型如何改变数字世界一样。
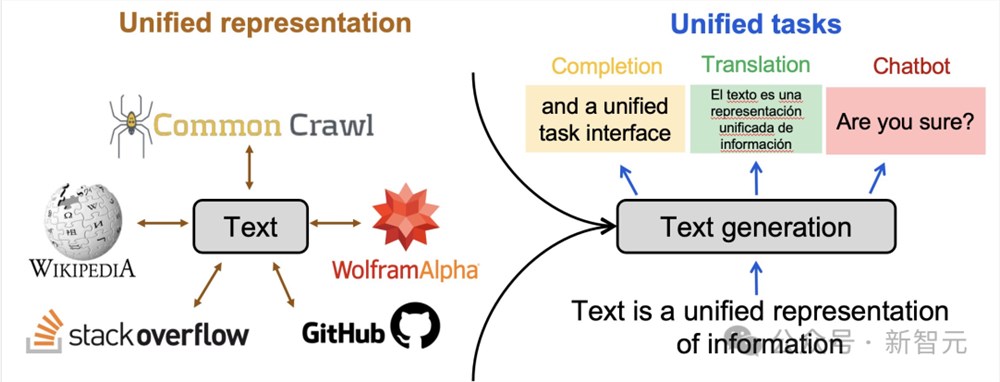
研究人员认为,与文本类似,视频可以作为一个统一的接口,吸收互联网知识并表征不同的任务。
例如,经典的计算机视觉任务可以被视为下一代帧生成任务(next-frame generation task)。
模型可以通过生成操作视频(例如「如何制作寿司」)来回答人们的问题,这可能比文本响应更直观。

视觉和算法推理也可以作为下一帧/视频生成任务。


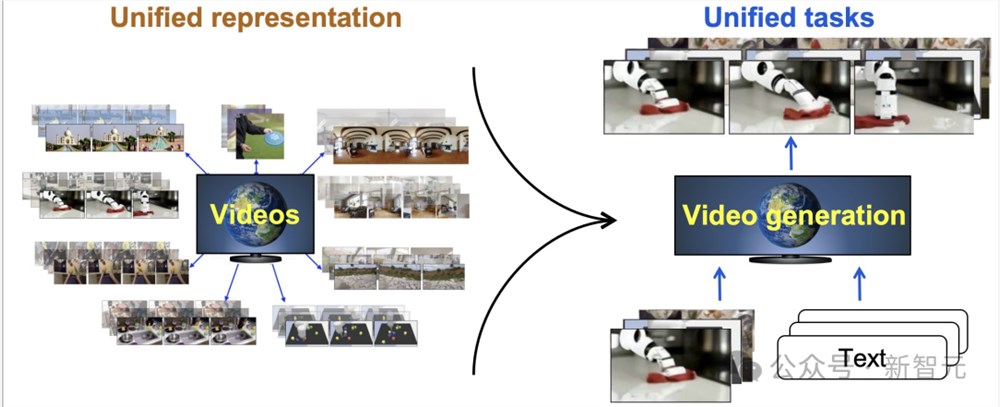
视频也可以统一不同实体(embodiment)的观察空间(observation space),因此可以使用单个视频生成模型为不同机器人生成视觉执行计划:

而且就像谷歌刚刚发布的世界生成模型Genie一样,视频生成也是复杂游戏的真实模拟器,可以与基于模型的规划相结合,或者用于创建游戏。
生成视频模拟器对于优化科学和工程领域的控制输入也很有用,在这些领域可以收集大量视频数据,但底层的物理动力学很难明确表达(例如,云运动、与软物体的交互)。

预测下一帧,会像预测下一个字那样改变世界
过去几年,从互联网文本数据集训练大语言模型(LLMs)的工作取得了巨大进展。
LLM在各种任务上的出色表现让人不禁想把人工智能的议程缩减为扩大这些系统的规模。
然而,大语言模型上取得的突破似乎也开始面临了很多的局限。
首先,可公开获取的文本数据的数量正变得越来越大。这将成为进一步扩展的瓶颈。
其次,也许更重要的是,仅靠自然语言可能不足以描述所有智能行为,也无法捕捉我们所处物理世界的所有信息(例如,想象一下仅用语言教人如何打结)。
虽然语言是描述高层次抽象概念的强大工具,但它并不总是足以捕捉物理世界的所有细节。
值得庆幸的是,互联网上有丰富的视频数据,仅YouTube上就有超过一万年的连续视频内容,其中包含了大量关于世界的知识信息。
然而,今天在互联网文本或视频数据上训练出来的机器学习模型却表现出了截然不同的能力。LLMs 已经能够处理需要复杂推理、工具使用和决策制定的复杂任务。
相比之下,视频生成模型的探索较少,主要集中在创建供人类消费的娱乐视频。
鉴于语言建模领域正在发生的范式转变,研究人员提出这样一个问题:
我们能否将视频生成模型提升到与语言模型类似的自主代理、模拟环境和计算引擎的水平,从而使机器人、自动驾驶和科学等需要视觉模式的应用能够更直接地受益于互联网视觉知识和预训练视频模型。
研究人员认为视频生成对于物理世界的意义就如同语言模型对于数字世界的意义。
为了得出这一观点,我们首先确定了使语言模型能够解决许多现实世界任务的关键组成部分:(1) 能够从互联网吸收广泛信息的统一表示法(即文本)、
(2) 统一的接口(即文本生成),通过它可以将不同的任务表达为生成建模,以及
(3) 语言模型能与外部环境(如人类、工具和其他模型)交互,根据外部反馈采取相应行动和优化决策,如通过人类反馈强化学习、规划、搜索(姚等人,2023年)和优化等技术。
从语言模型的这三个方面出发,研究人员发现:
(1) 视频可以作为一种统一的表征,吸收物理世界的广泛信息;
(2) 视频生成模型可以表达或支持计算机视觉、嵌入式人工智能和科学领域的各种任务;
(3) 视频生成作为一种预训练目标,为大型视觉模型、行为模型和世界模型引入了互联网规模的监督,从而可以提取动作、模拟环境交互和优化决策。
为了进一步说明视频生成如何对现实世界的应用产生深远影响,他们深入分析通过指令调整、上下文学习、规划和强化学习(RL)等技术,在游戏、机器人、自动驾驶和科学等领域将视频生成用作任务求解器、问题解答、策略/代理和环境模拟器。
视频生成的前提设置
研究人员将视频片段表示为一系列图像帧 x = (x0, ..., x t )。图像本身可被视为具有单帧 x = (x0, ) 的特殊视频。条件视频生成模型是条件概率 p(x|c),其中 c 是条件变量。条件概率 p(x | c) 通常由自回归模型、扩散模型或掩蔽Transformer模型进行因子化。
根据不同的因式分解,p(x | c)的采样要么对应于连续预测图像(斑块),要么对应于迭代预测所有帧(x0,...,x t )。
根据条件变量 c 的内容,条件视频生成可以达到不同的目的。
统一表征法和任务接口
在本节中,作者首先介绍了视频是如何作为一种统一的表征,从互联网中捕捉各种类型的信息,从而形成广泛的知识。
然后,讨论如何将计算机视觉和人工智能中的各种任务表述为条件视频生成问题,从而为现实世界中的视频生成决策提供基础。
作为信息统一表征的视频
虽然互联网文本数据通过大型语言模型为数字/知识世界提供了很多价值,但文本更适合捕捉高级抽象概念,而不是物理世界的低级细节。
研究人员列举几类难以用文本表达,但可以通过视频轻松捕捉的信息。

-视觉和空间信息:这包括视觉细节(如颜色、形状、纹理、光照效果)和空间细节(如物体在空间中的排列方式、相对位置、距离、方向和三维信息)。
与文本格式相比,这些信息自然是以图像/视频格式存在的。
-物理和动力学:这包括物体和环境如何在物理上相互作用的细节,如碰撞、操作和其他受物理规律影响的运动。
虽然文字可以描述高层次的运动(如 "一辆汽车在街道上行驶"),但往往不足以捕捉低层次的细节,如施加在车辆上的扭矩和摩擦力。视频可以隐含地捕捉到这些信息。
-行为和动作信息:这包括人类行为和代理动作等信息,描述了执行任务(如如何组装一件家具)的低层次细节。
与精确的动作和运动等细节信息相比,文本大多能捕捉到如何执行任务的高级描述。
为什么是视频?
有人可能会问,即使文本不足以捕捉上述信息,为什么还要用视频呢?
视频除了存在于互联网规模之外,还可以为人类所解读(类似于文本),因此可以方便地进行调试、交互和安全推测。
此外,视频是一种灵活的表征方式,可以表征不同空间和时间分辨率的信息,例如以埃级(10-10m)运动的原子和以每秒万亿帧速度运动的光。
作为统一任务接口的视频生成
除了能够吸收广泛信息的统一表征外,研究人员还从语言建模中看到,需要一个统一的任务接口,通过它可以使用单一目标(如下一个标记预测)来表达不同的任务。
同时,正是信息表征(如文本)和任务接口(如文本生成)之间的一致性,使得广泛的知识能够转移到特定任务的决策中。
经典计算机视觉任务
在自然语言处理中,有许多任务(如机器翻译、文本摘要、问题解答、情感分析、命名实体识别、语音部分标记、文本分类等)都是视觉任务。
文本分类、对话系统,传统上被视为不同的任务,但现在都统一到了语言建模的范畴内。
这使得不同任务之间的通用性和知识共享得以加强。
同样,计算机视觉也有一系列广泛的任务,包括语义分割、深度估计、表面法线估计、姿态估计、边缘检测和物体跟踪。

最近的研究表明,可以
