
Python爬取京东的商品分类与链接
前言
本文主要的知识点是使用Python的BeautifulSoup进行多层的遍历。

如图所示。只是一个简单的哈,不是爬取里面的隐藏的东西。
示例代码
from bs4 import BeautifulSoup as bs
import requests
headers = {
"host": "www.jd.com",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36 Core/1.47.933.400 QQBrowser/9.4.8699.400",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"
}
session = requests.session()
def get_url():
renspned = bs(session.get('http://www.jd.com/',headers = headers).text,'html.parser')
for i in renspned.find("div", {"class": "dd-inner"}).find_all("a",{"target":"_blank"}):
print(i.get_text(),':',i.get('href'))
get_url()
运行这段代码以及达到了我们的目的。
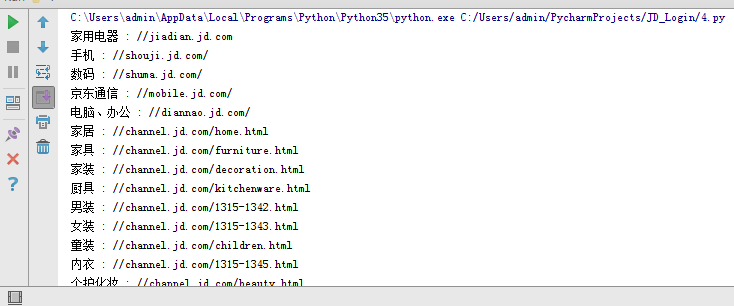
我们来解读一下这段代码。
首先我们要访问到京东的首页。
然后通过BeautifulSoup对访问到的首页进行解析。
这个时候,我们就要定位元素,来获取我们需要的东西了。
在浏览器中通过F12,我们可以看到下图所示的东西:
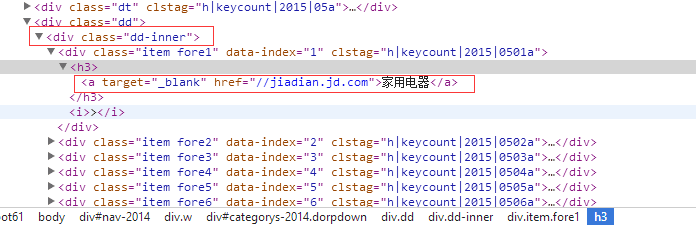
我们来看看下面这句代码:
for i in renspned.find("div", {"class": "dd-inner"}).find_all("a",{"target":"_blank"})
这一行代码完全满足我们的需求,首先用find方法,定位到了class=“dd-inner”的div,然后使用find_all对该标签下所有的a标签。
最后,我想打印出所有的商品分类以及对应的链接,于是,我使用了i.get_text()和i.get('href')的方法终于获取到了商品分类和对应的链接。
总结
其实不是很难,主要是要用对方法。笔者因为是初学方法没有用对。花了差不多两天时间才搞定。这里也是告诉大家,可以使用find().find_all()的方法进行多层的遍历。以上就是我利用Python爬取京东的商品分类与链接的一些经验,希望对大家学习python能有所帮助。
python实现实时监控文件的方法
在业务稳定性要求比较高的情况下,运维为能及时发现问题,有时需要对应用程序的日志进行实时分析,当符合某个条件时就立刻报警,而不是被动等
使用python绘制常用的图表
本文介绍如果使用python汇总常用的图表,与Excel的点选操作相比,用python绘制图表显得比较比较繁琐,尤其提现在对原始数据的处理上。但两者在绘制图
Python连接DB2数据库
在工作中遇到了这样的情况,项目中需要连接IBM的关系型数据库(DB2),关于这方面的库比较稀少,其中ibm_db是比较好用的一个库,网上也有教程,但是好
